Abstract
Constrained Reinforcement Learning employs trajectory-based cost constraints (such as expected cost, Value at Risk, or Conditional VaR cost) to compute safe policies. The challenge lies in handling these constraints effectively while optimizing expected reward. Existing methods convert such trajectory-based constraints into local cost constraints, but they rely on cost estimates, leading to either aggressive or conservative solutions with regards to cost. We propose an unconstrained formulation that employs reward penalties over states augmented with costs to compute safe policies. Unlike standard primal-dual methods, our approach penalizes only infeasible trajectories through state augmentation. This ensures that increasing the penalty parameter always guarantees a feasible policy, a feature lacking in primal-dual methods. Our approach exhibits strong empirical performance and theoretical properties, offering a fresh paradigm for solving complex Constrained RL problems, including rich constraints like expected cost, Value at Risk, and Conditional Value at Risk. Our experimental results demonstrate superior performance compared to leading approaches across various constraint types on multiple benchmark problems.
Contribution
We provide a re-formulation of the constrained RL problem through augmenting the state space with cost accumulated so far and employing reward penalties when cost constraint is violated.
We show theoretically the difference between our reward penalties and Lagrangian penalties. We also show that the reward penalties employed in the new formulation are not ad-hoc and can equivalently represent different constraints, i.e. risk-neutral, chance constrained (or VAR) and CVaR constraints.
We modify existing RL methods to solve the re-formulated RL problem with augmented state space and more importantly employing reward penalties when constraints are violated.
We demonstrate the utility of our approach by comparing against leading approaches for constrained RL on multiple benchmark problems for different types of constraints. We show that our approaches are able to outperform leading Constrained RL approaches with different constraints.
Results with Risk-Neutral Constraint
The experiment environments are Modified GridWorld, Puddle, Highway and Safety Gym.
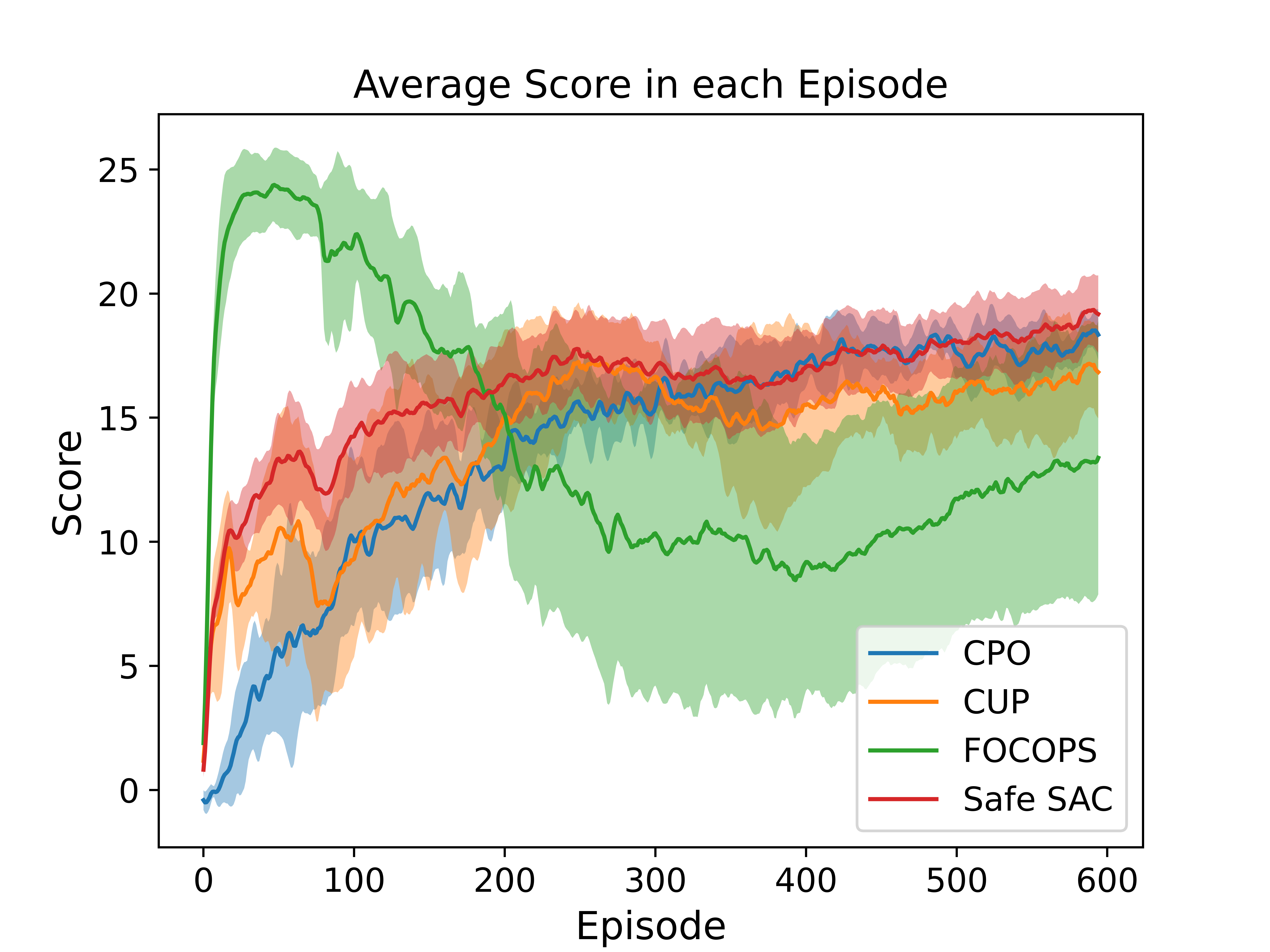
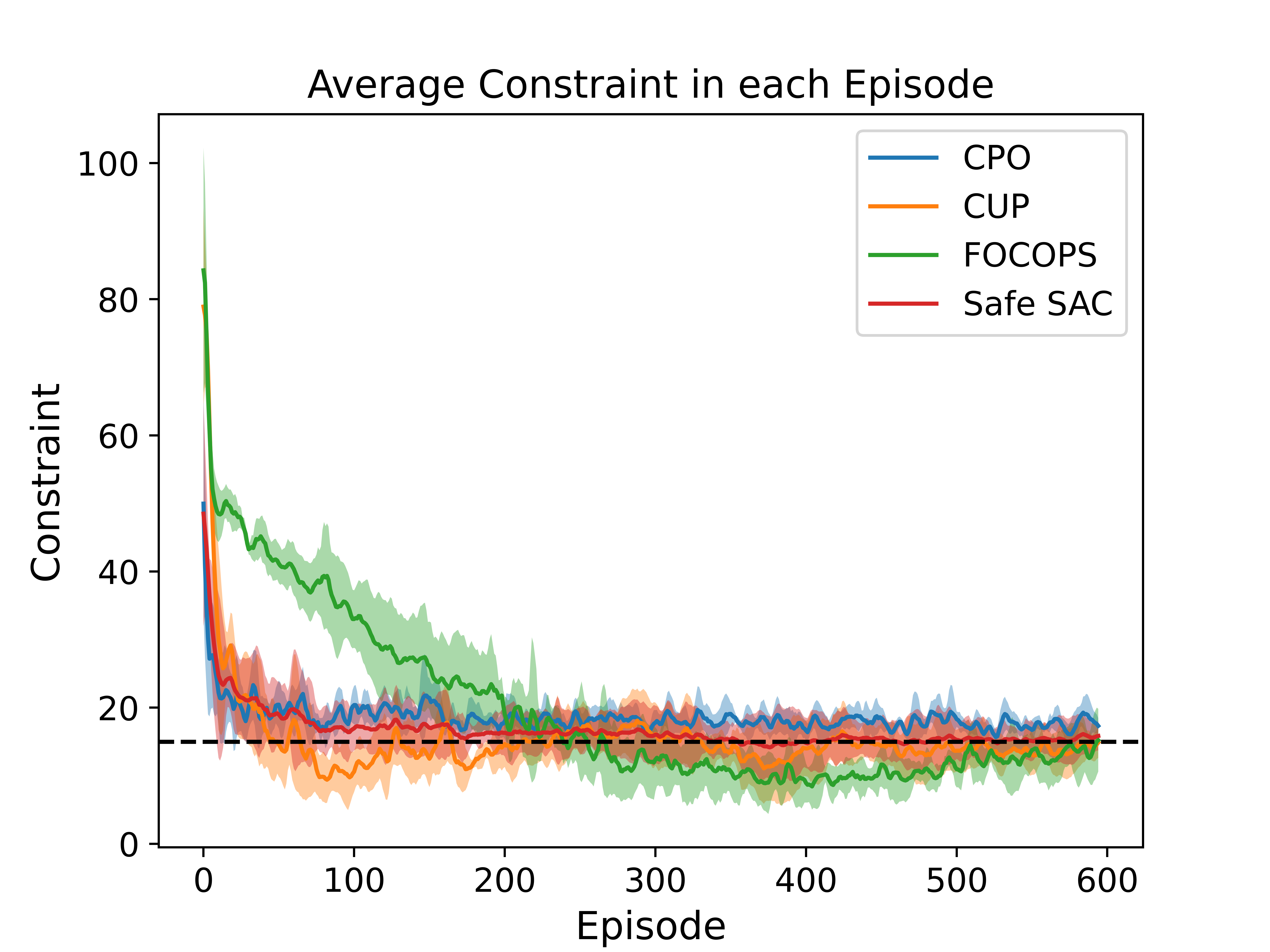
Comparison on SafetyPointGoal environment
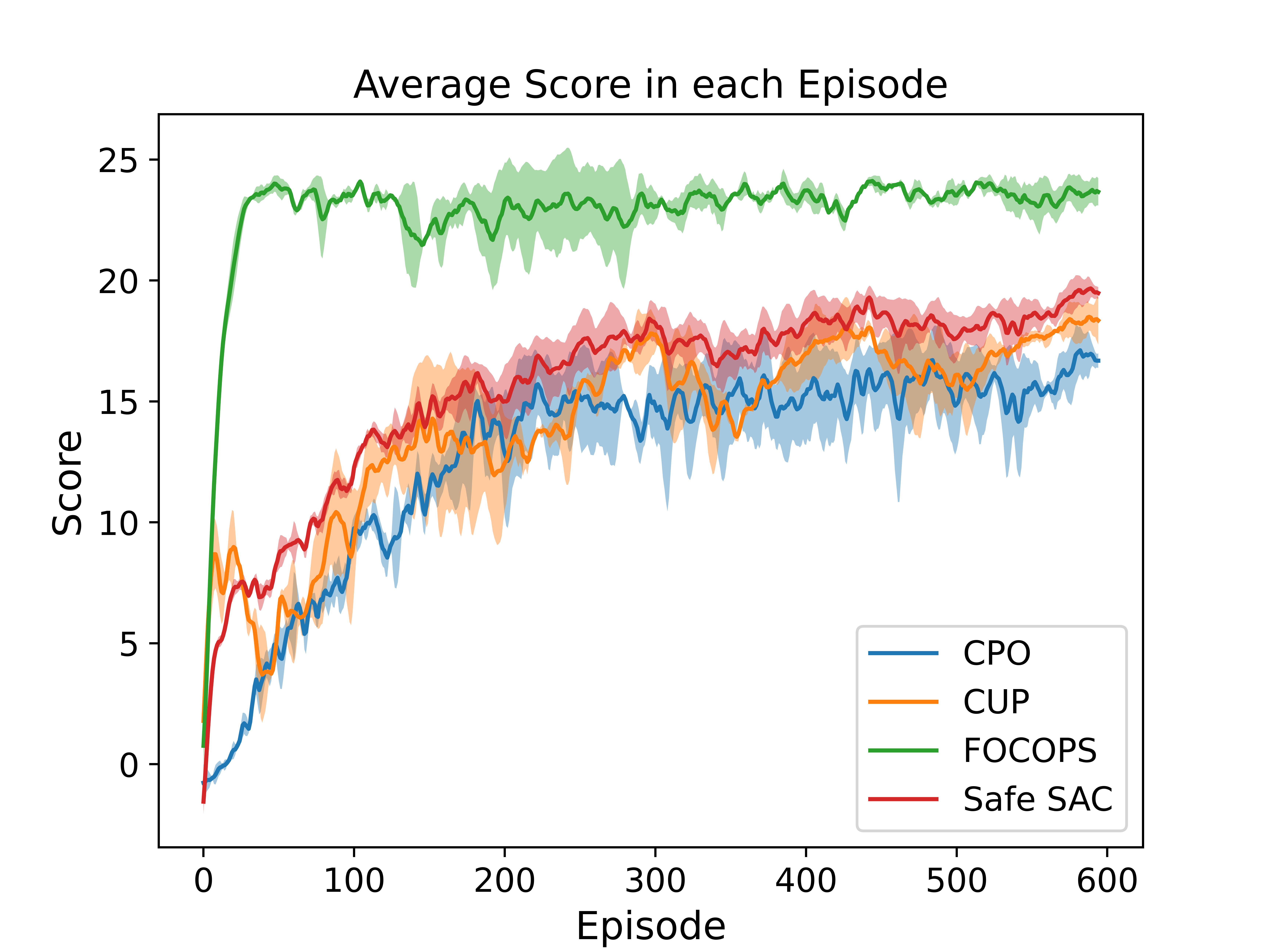
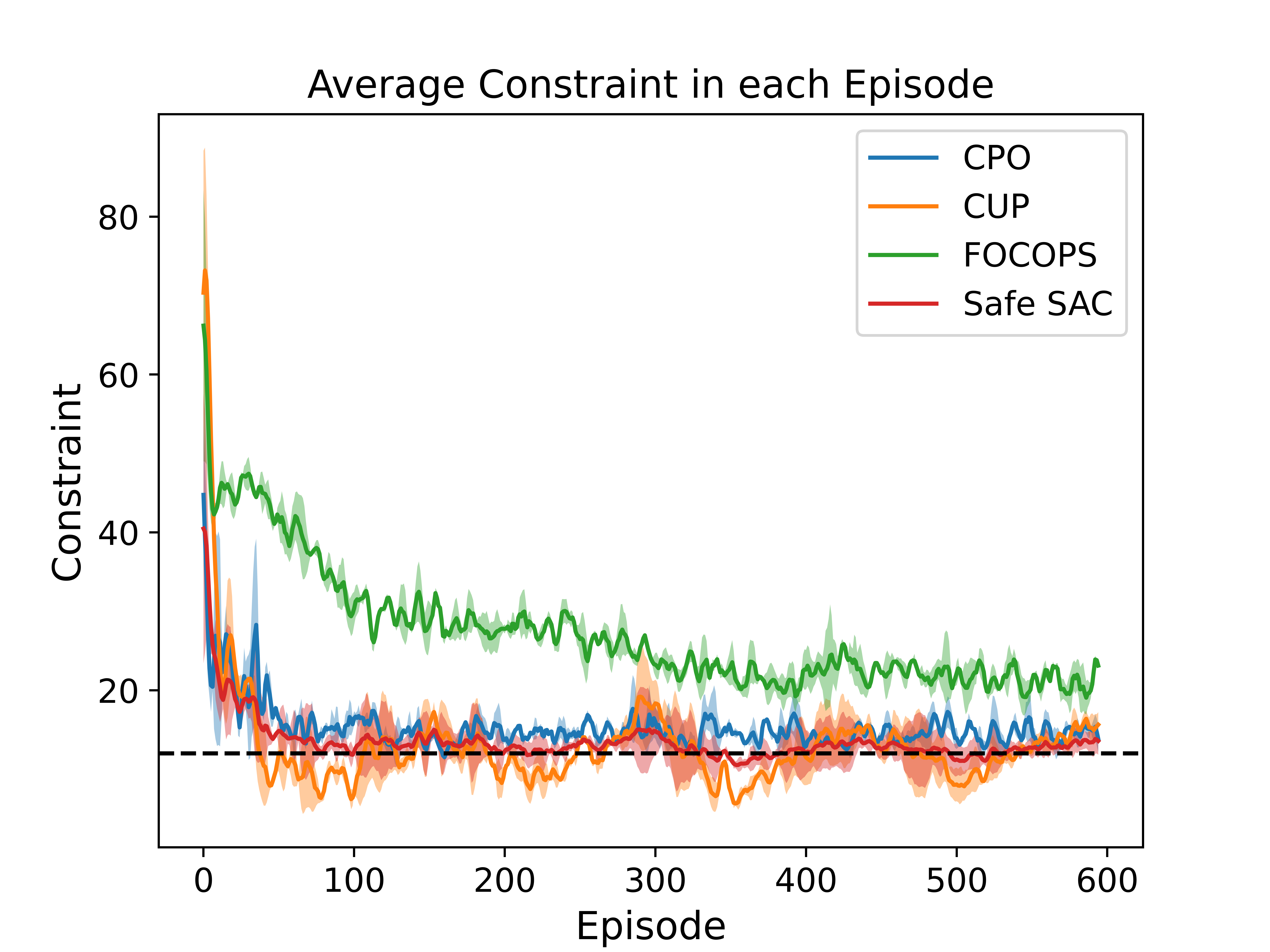
Comparison on SafetyPointGoal-v3 Environment
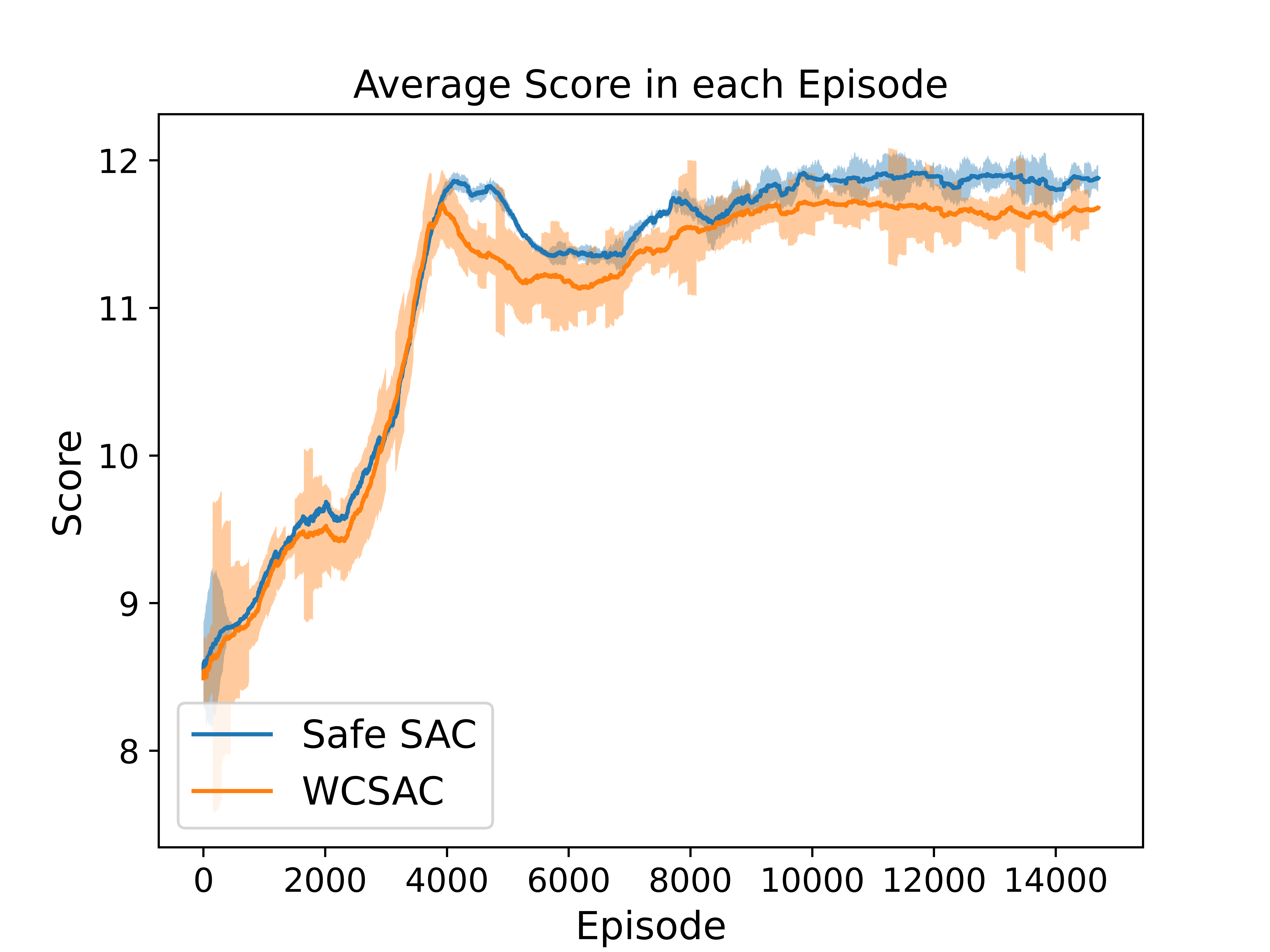
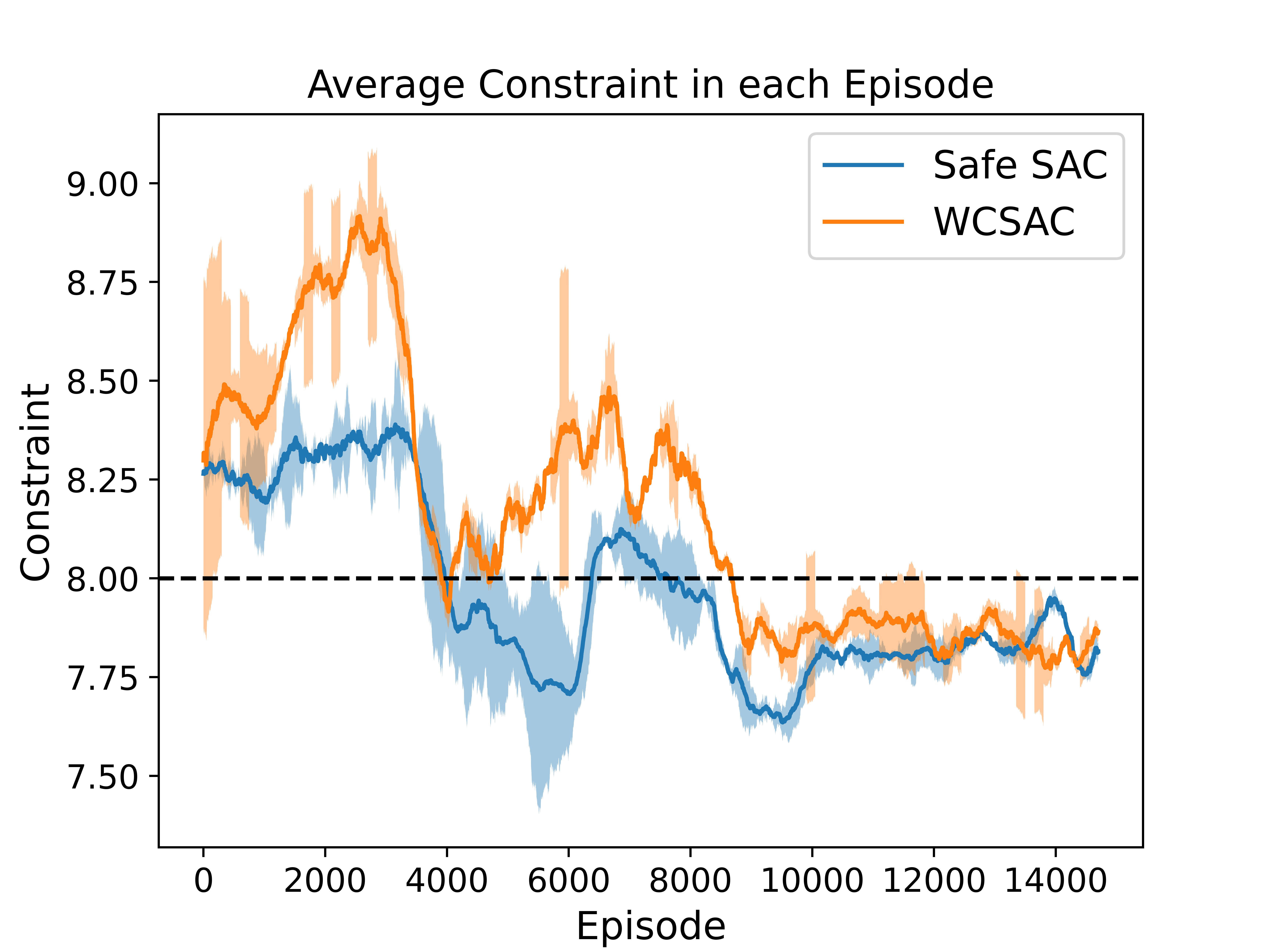
Experiment with CVaR Constraint in Merge Environment
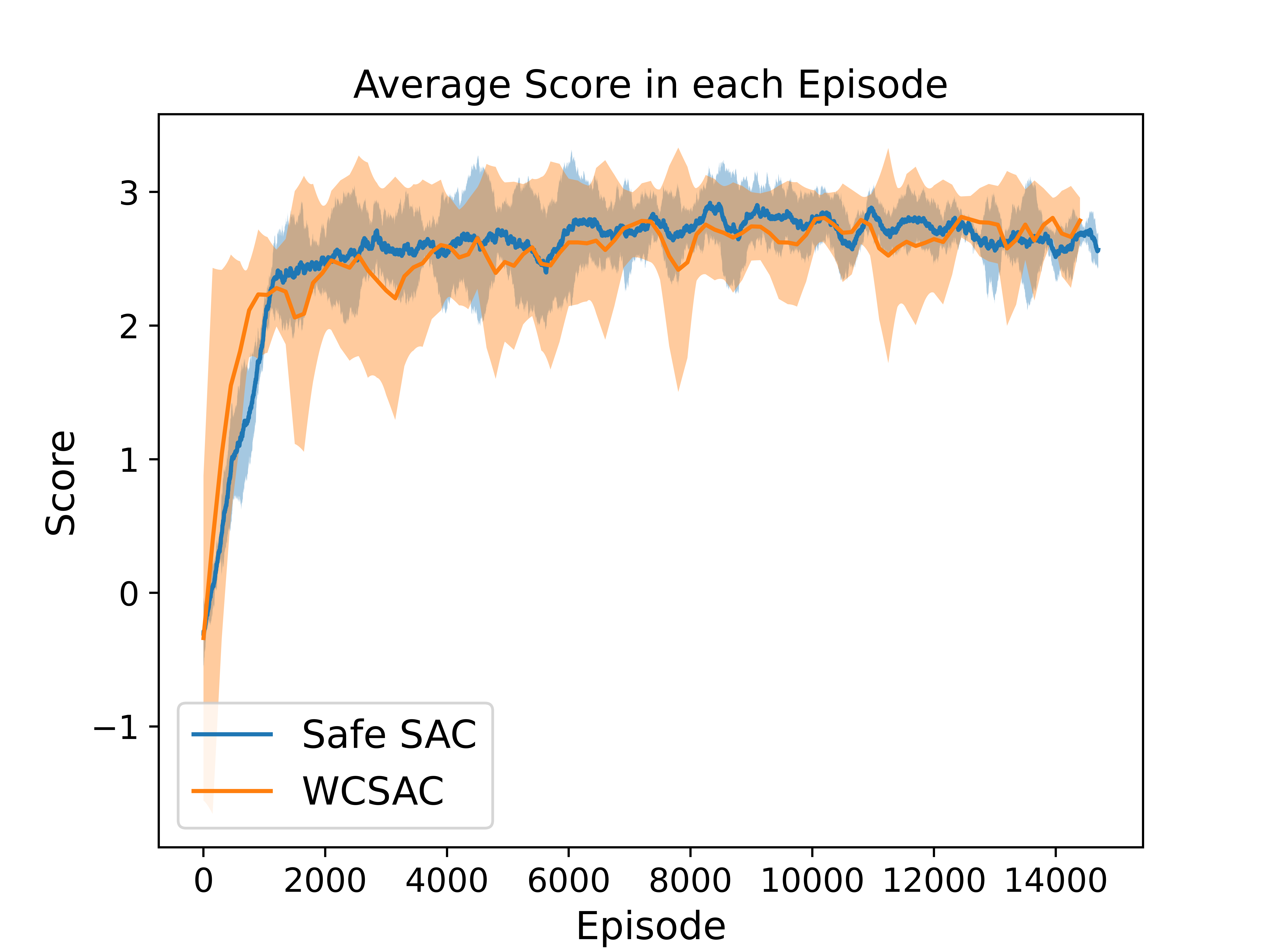
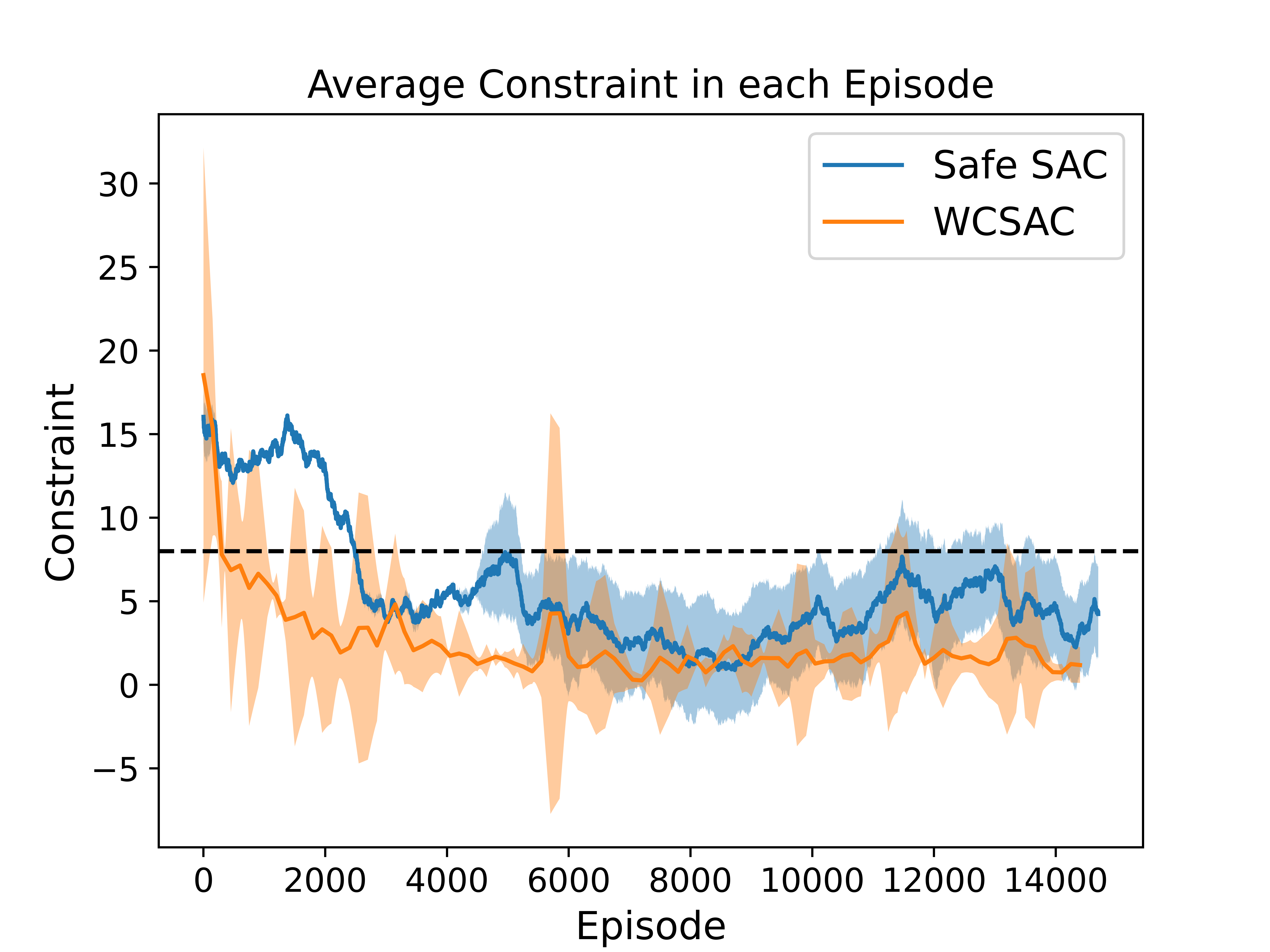
Experiment with CVaR Constraint in SafetyGym Environment
To investigate the impact of state augmentation and reward penalty, we conduct an ablation analysis using GridWorld and Highway environments.
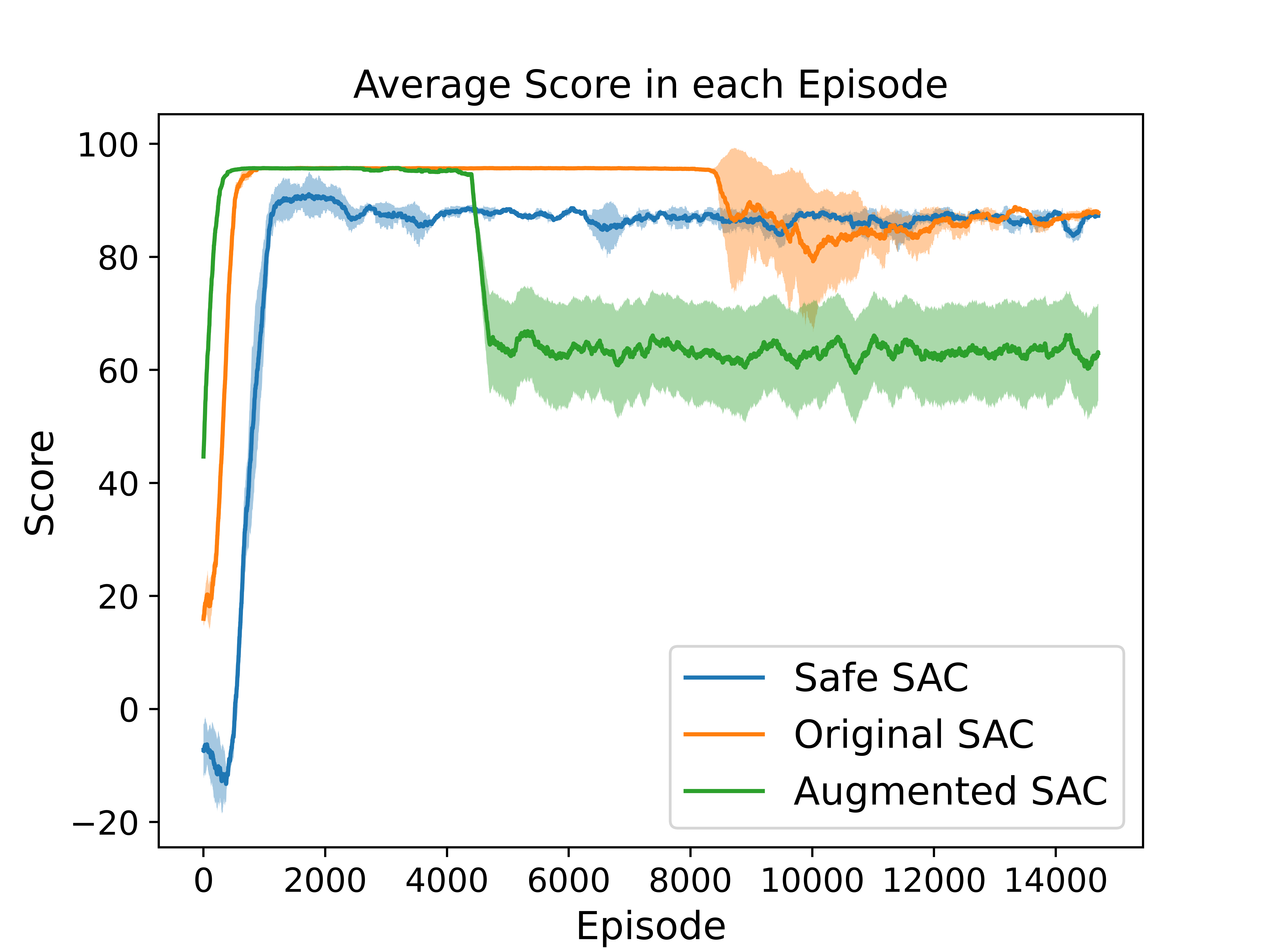
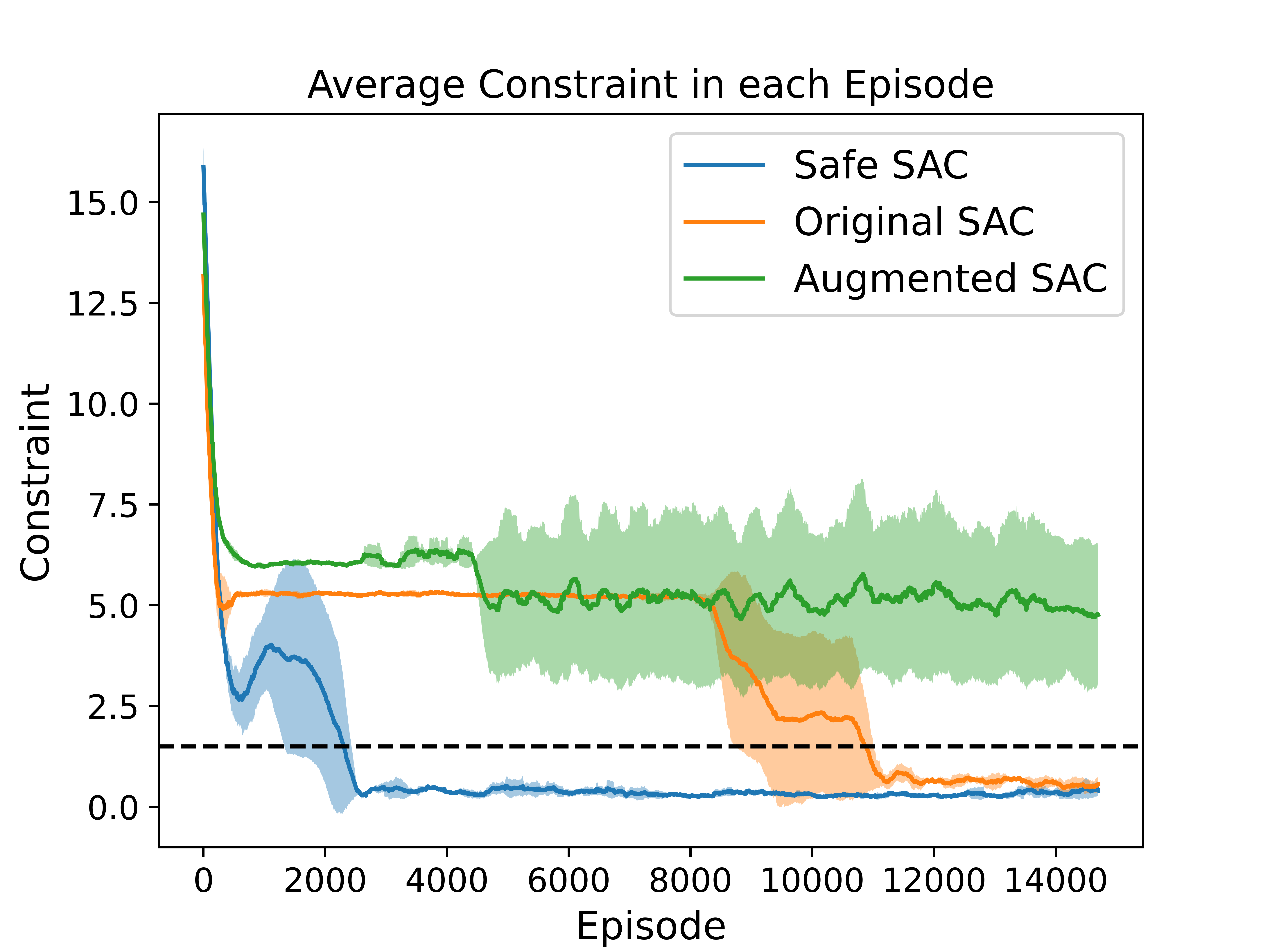
Ablation Analysis with GridWorld Environment
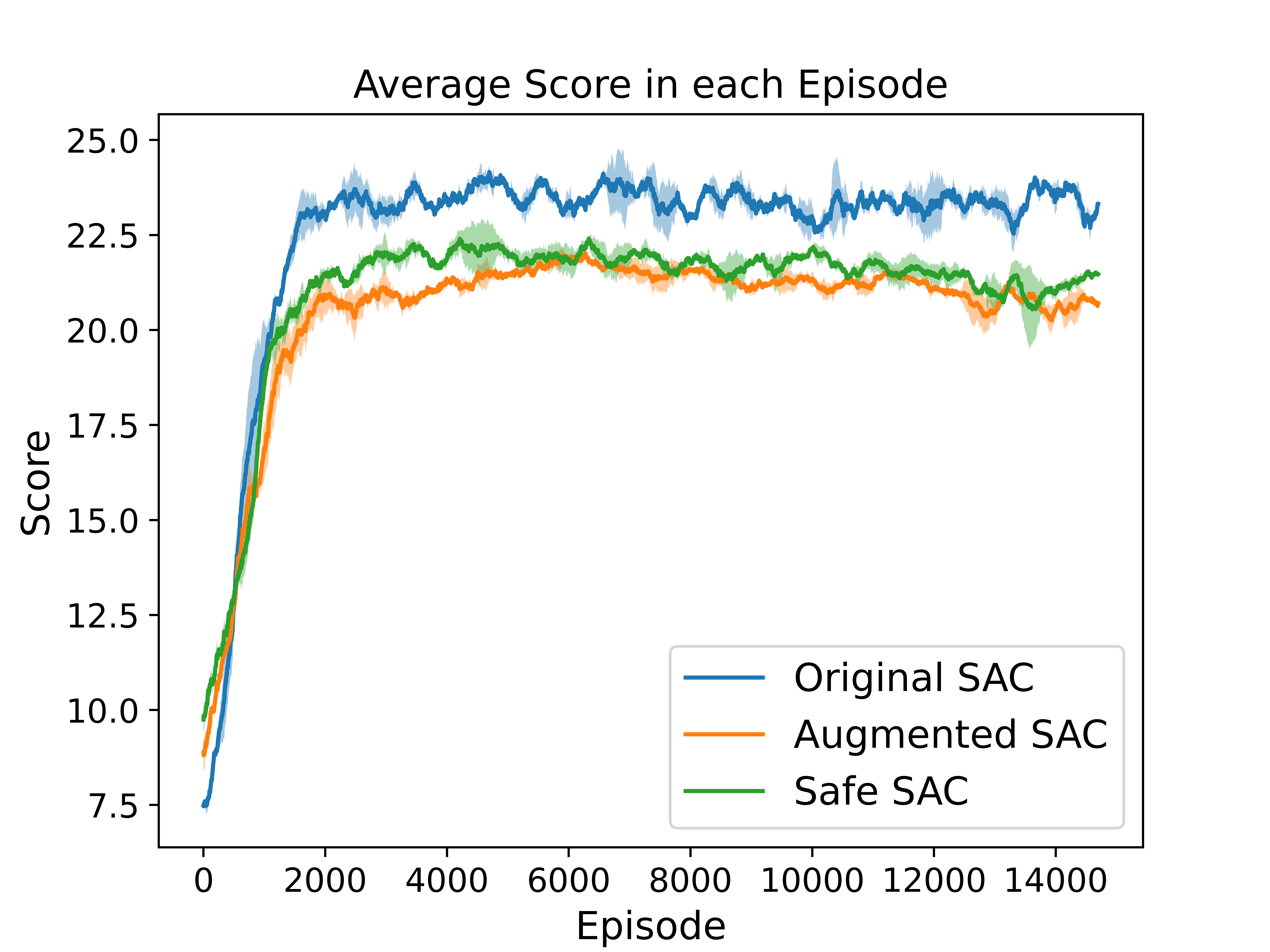
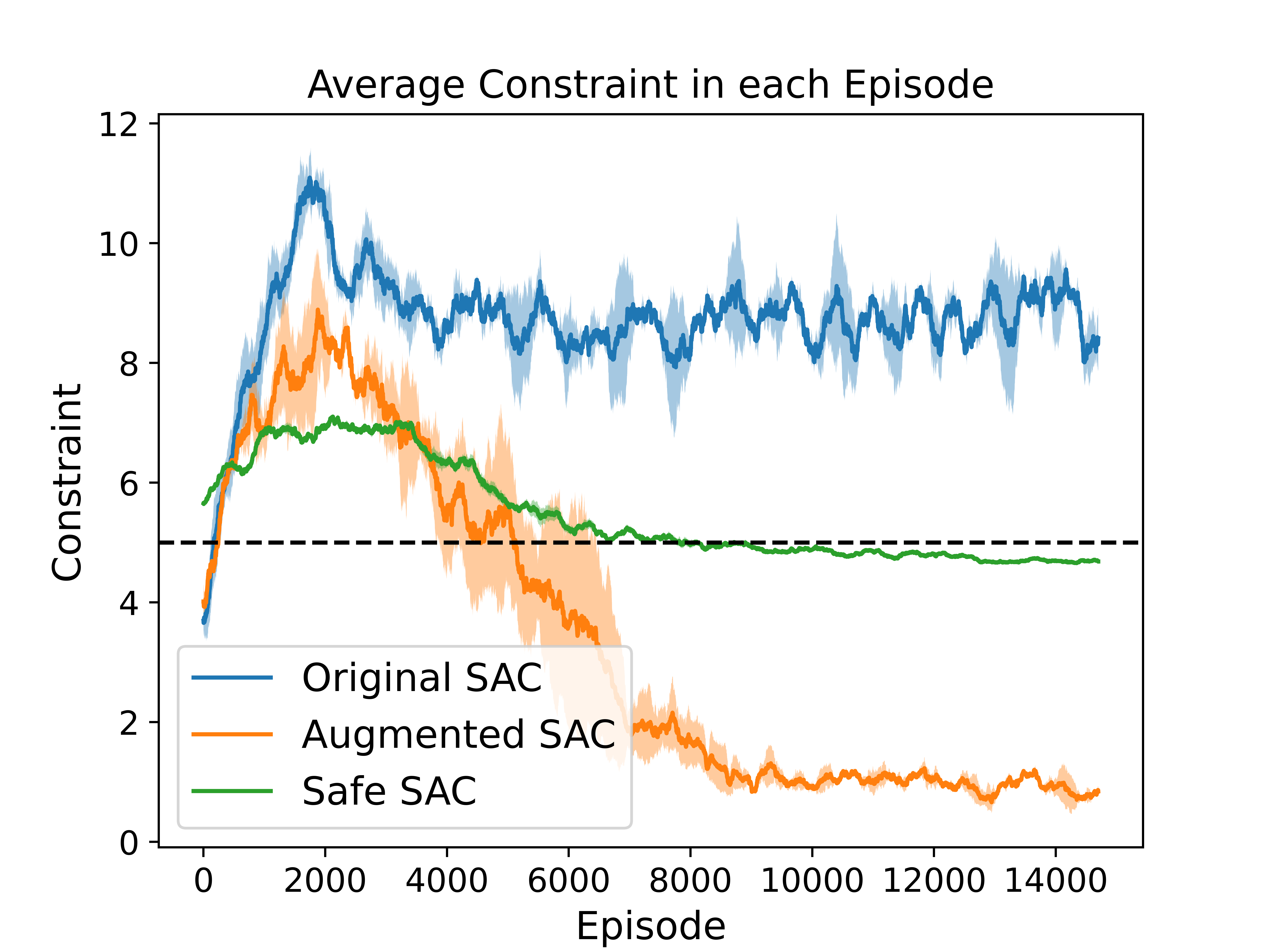
Ablation Analysis with Highway Environment
To investigate the impact of different reward penalty values on the performance, we conduct experiments on GridWorld and Highway using Safe SAC.
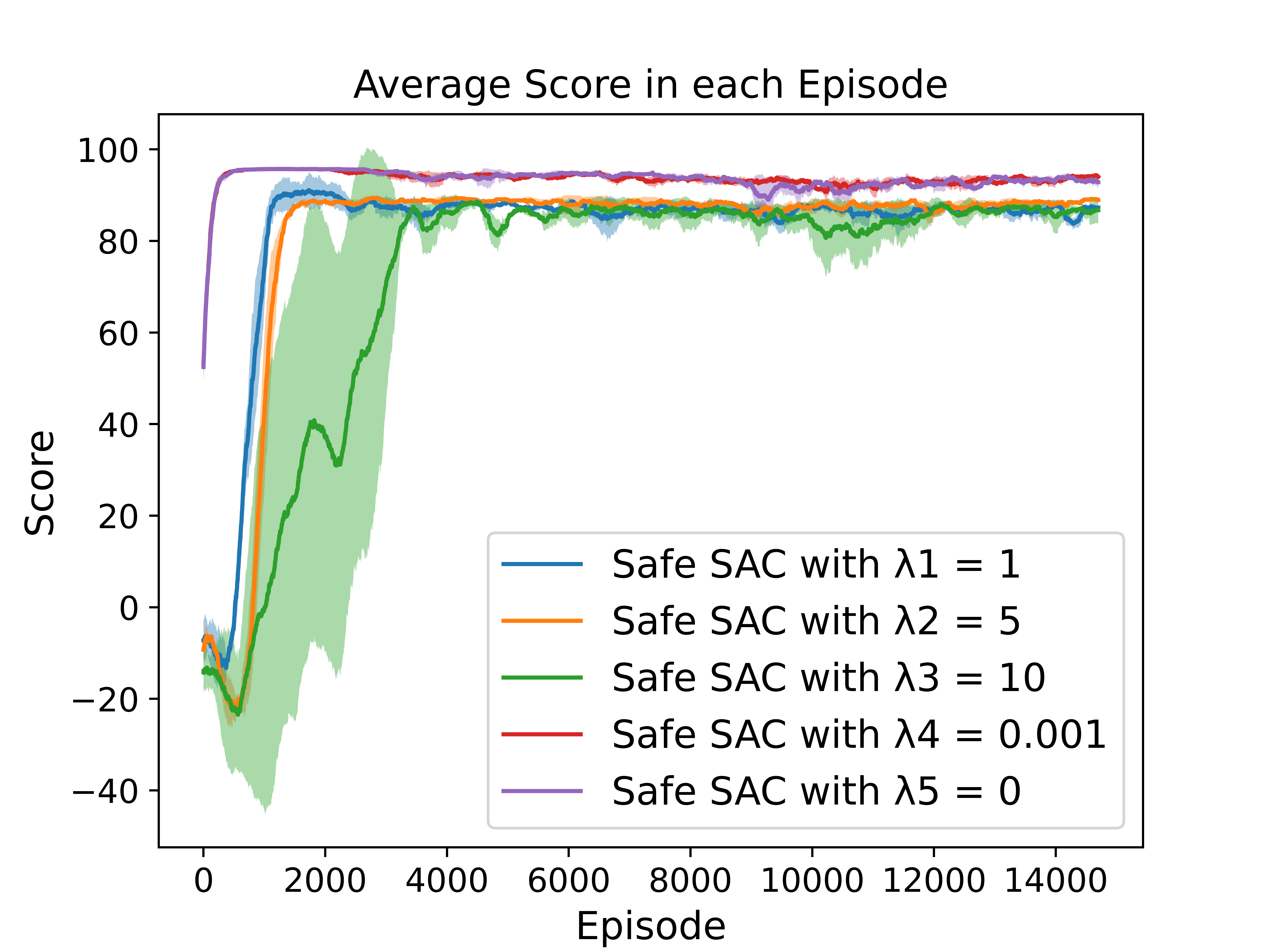
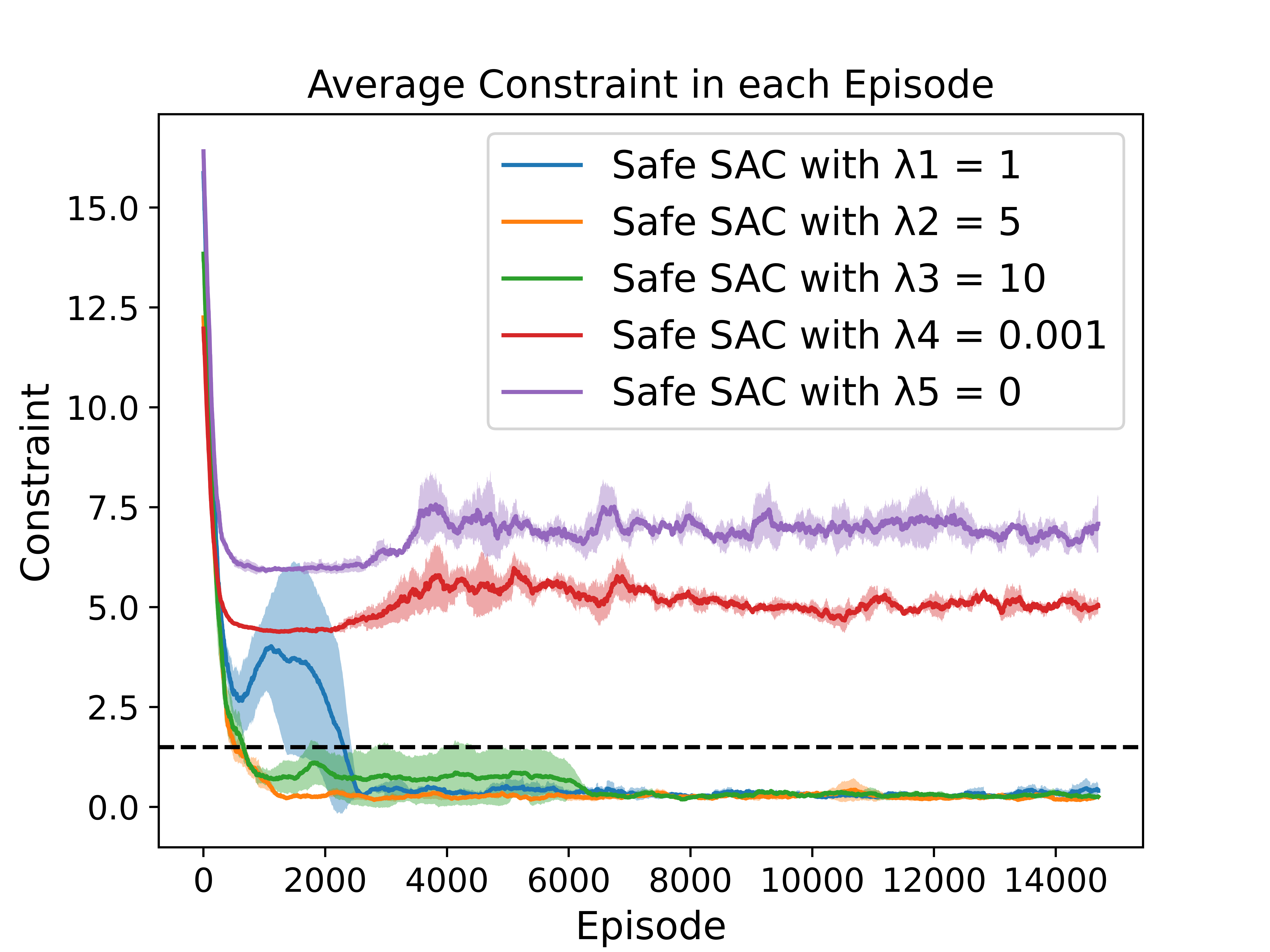
Experiment in GridWorld with Different Reward Penalties
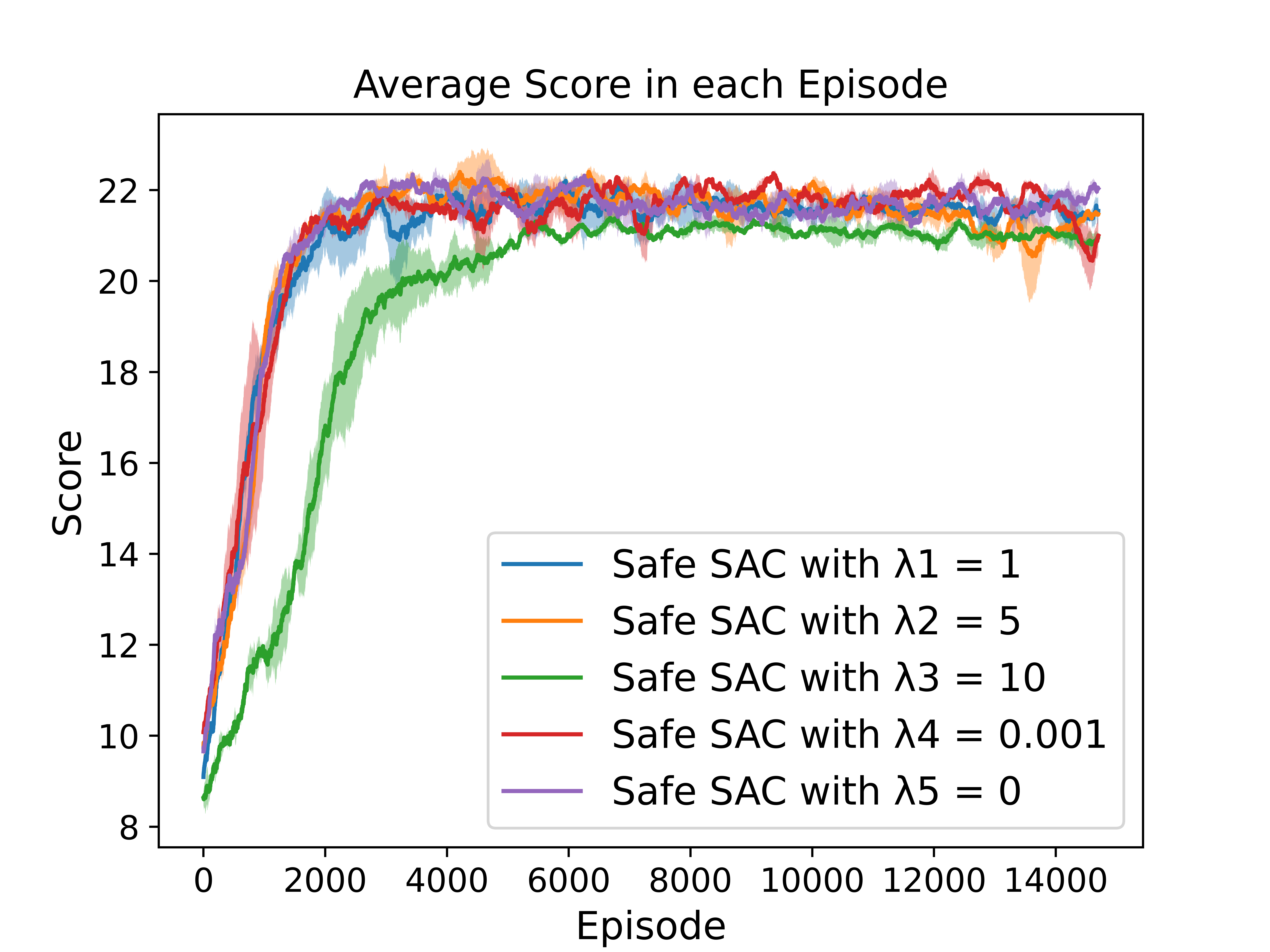
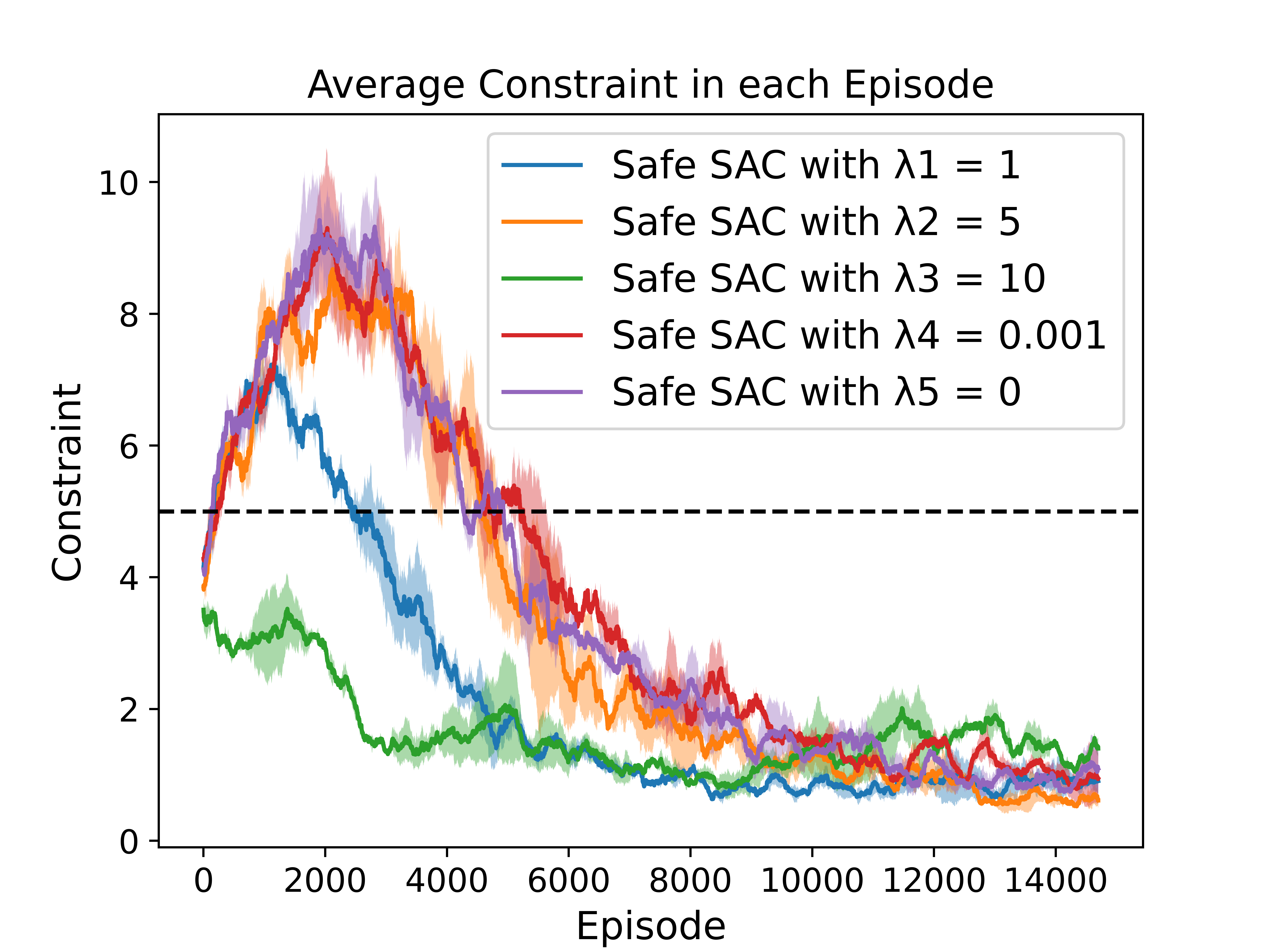
Experiment in Highway with Different Reward Penalties
Acknowledgements
This research/project is supported by the National Research Foundation Singapore and DSO National Laboratories under the AI Singapore Programme (AISG Award No: AISG2-RP-2020-017)BibTeX
Tentatively Unavailable